12 Data Engineering Concepts You Need to Know to Build Powerful Data Systems
Data Engineering isn’t complicated , It’s just badly explained.

Most people focus on tools.
But what really matters are the core concepts behind them.
If you’re building data pipelines, platforms, or analytics systems, here are 12 data engineering concepts worth understanding:
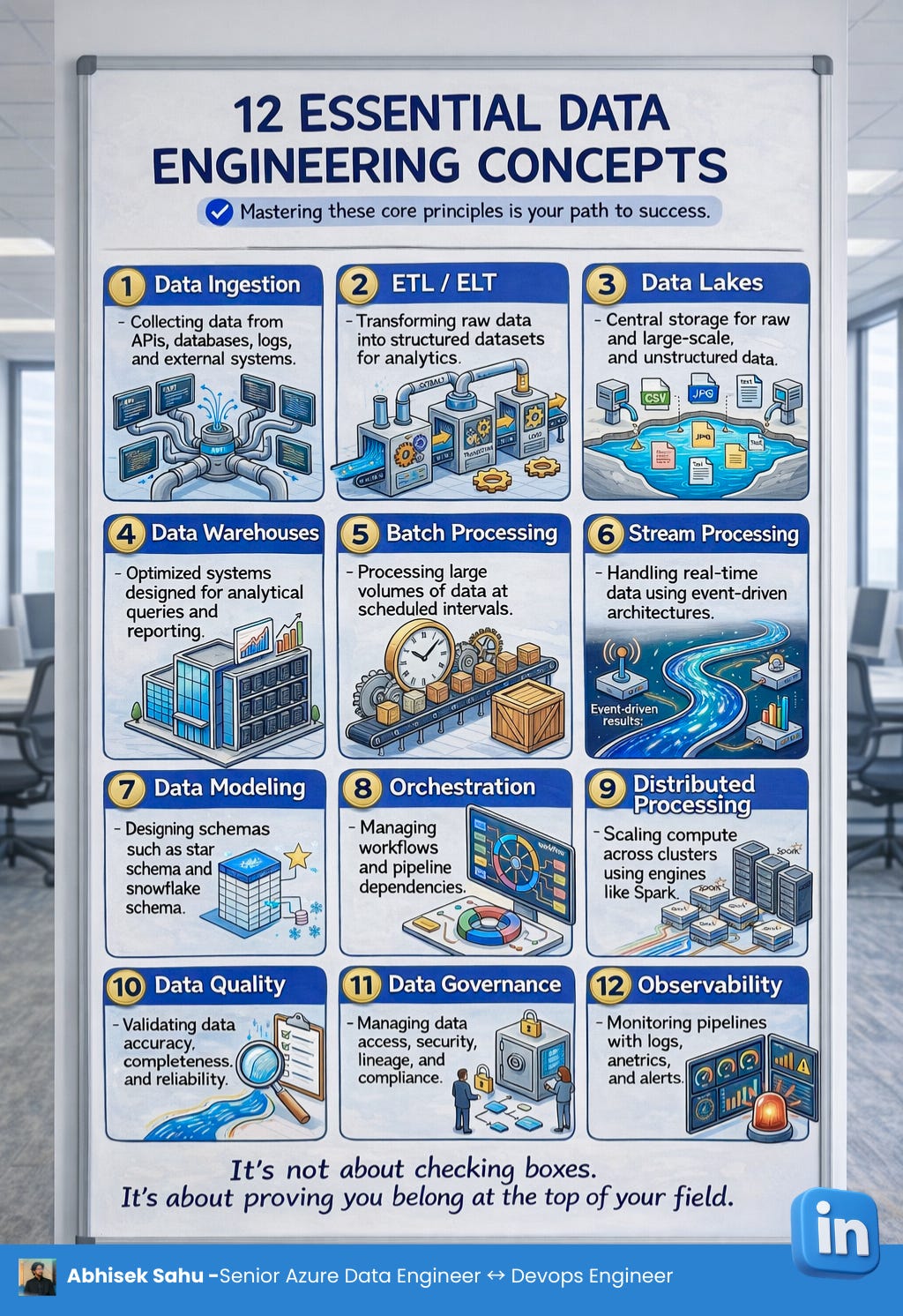
1. Data Ingestion
→ Collecting data from multiple sources
↳ APIs, databases, logs, applications, events
2. ETL / ELT
→ Converting raw data into usable datasets
↳ ETL: Extract → Transform → Load
↳ ELT: Extract → Load → Transform
3. Data Lakes
→ Central storage for massive volumes of raw data
↳ structured + semi-structured + unstructured
4. Data Warehouses
→ Systems optimized for analytics and reporting
↳ BI dashboards, business queries, analytics teams
5. Batch Processing
→ Processing large datasets at scheduled intervals
↳ daily reports, periodic transformations
6. Stream Processing
→ Processing data continuously as events happen
↳ fraud detection, monitoring, real-time analytics
7. Data Modeling
→ Structuring data into schemas for faster analysis
↳ star schema, snowflake schema
8. Orchestration
→ Managing pipeline dependencies and scheduling workflows
↳ ensuring jobs run in the correct order
9. Distributed Processing
→ Splitting workloads across multiple machines
↳ used in big data platforms
10. Data Quality
→ Ensuring data is accurate, consistent, and reliable
↳ trusted dashboards and better decisions
11. Data Governance
→ Managing data access, lineage, security, and compliance
↳ trusted and controlled data environments
12. Observability
→ Monitoring pipelines with logs, metrics, and alerts
↳ faster debugging and reliable data systems
The important lesson:
Tools change every few years.
But the foundations of data engineering stay the same.
Master the concepts first.
The tools will become much easier to learn.
♻️ Restack to help others grow
🔔 Follow Abhisek Sahu for more
🤝 Linkedin : https://www.linkedin.com/in/abhisek-sahu-84a404b1/